The Otoritas Jasa Keuangan (OJK) is an Indonesian government entity which regulates and supervises the financial services sector. Which means it also oversees one of the increasingly popular technology-based financial services in Indonesia, peer-to-peer (P2P) lending.
There has been many cases of how Indonesian P2P lending companies (often unlicensed) have been increasingly predatory practices of these so-called "peer-to-peer" lending services, and their method of debt collection has been particularly egregious.
This led the OJK to publish a periodically updated list of P2P lending companies on their website, which also helps provide an open data repository of the companies they recognise and approve. However, many of the practices that the OJK had done in publishing these information goes against the spirit of open data. Let me explain why.
I run Pinjollist along with @mathdroid, a platform providing a searchable database of all P2P lending companies that are registered and apprived by the OJK. We provide our data through a Google spreadsheet as well as a consumable JSON API.
However, we still rely on the OJK to update our data periodically. We do have tools to process and store them, but in most times, we had to manually input these data because of OJK's inconsistencies. Here are some we had to deal with while adding/removing platforms from the list.
Inconsistent file format
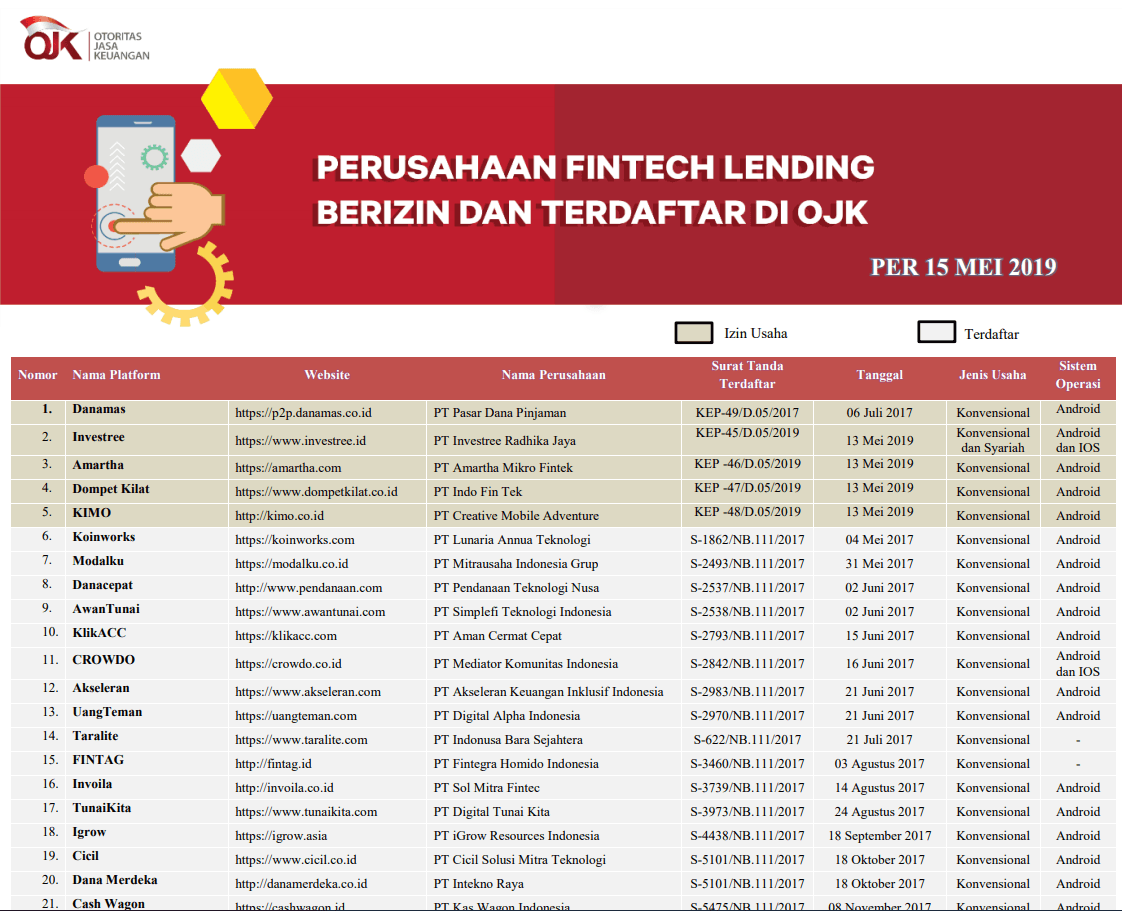
Here's a list of all the four file names (verbatim) of the data provided by the OJK from all their circulars. See if you spot anything wrong.
Direktori Fintech per Juni 2018.xlsxPerusahaan Fintech Lending Berizin dan Terdaftar di OJK - Februari 2019.pdf.pdfPenyelenggara Fintech Terdaftar dan Berizin Mei 2019.pdfPenyelenggara Fintech Terdaftar dan Berizin di OJK per 31 Mei 2019.pdf
First things first, the file names themselves are inconsistent, which was mostly just a nitpick from my end. But most importantly, every single circular published since February 2019 has been published in the PDF format, as opposed to the computer-readable Excel format in the first edition of the directory.
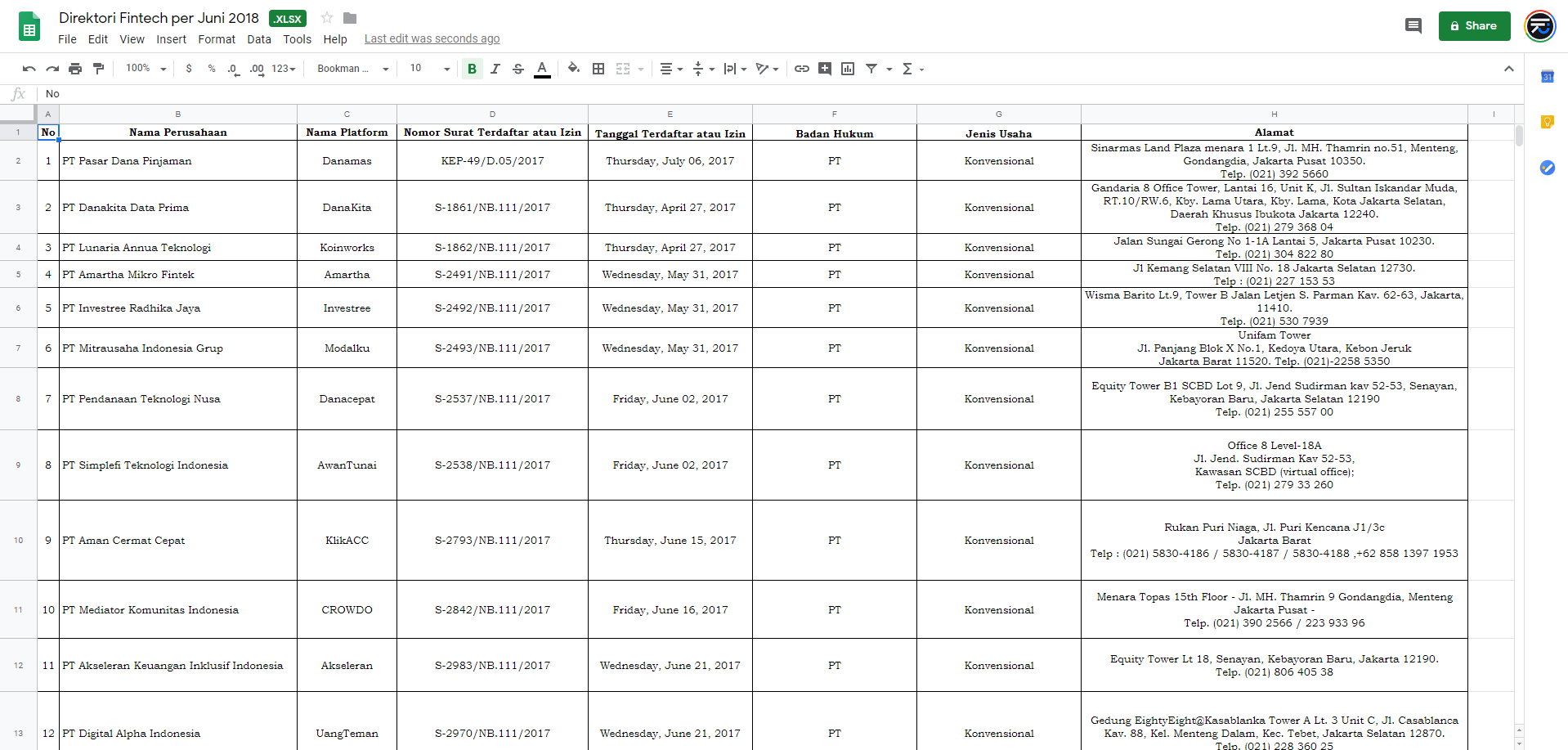
Data columns appearing and disappearing each circular
The first Excel sheet published by the OJK had the base essential informations. Company name and address, platform name, the date of registration as well as the registration number. Their February 2019 circular for some reason omitted the company's address, which was an essential information! The May 2019 then added a less-essential information of which OS the platform runs on.
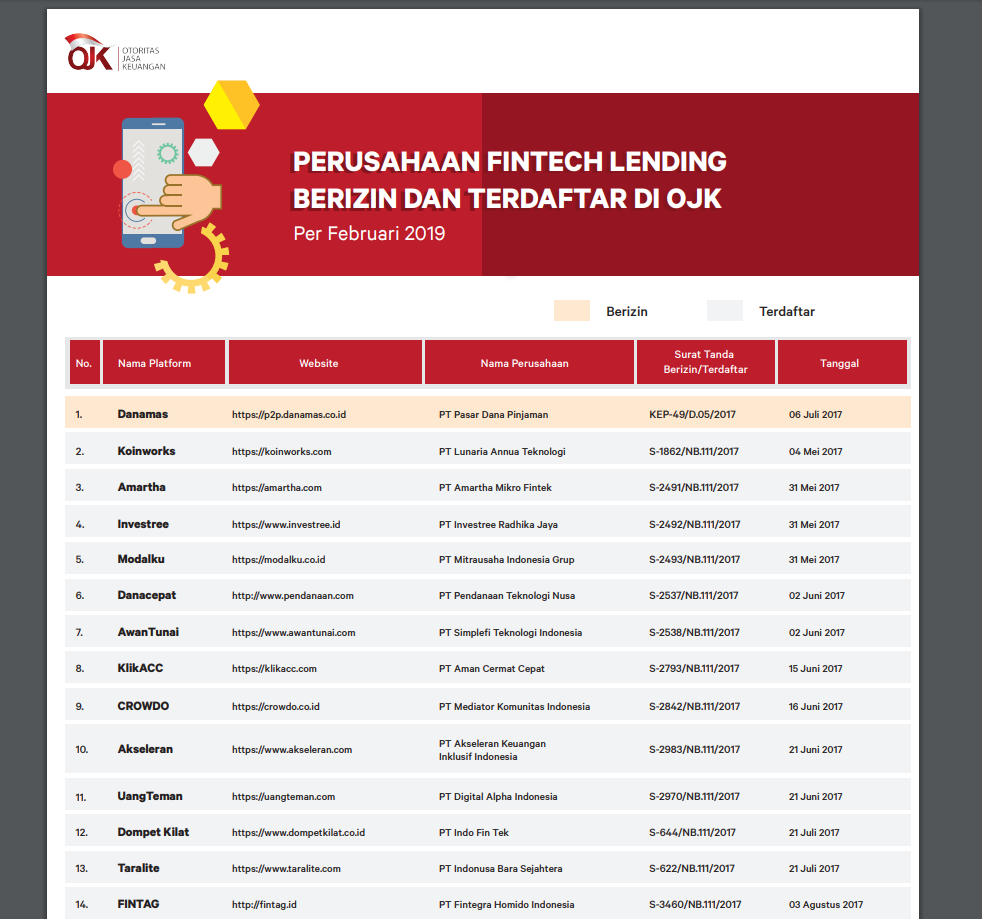
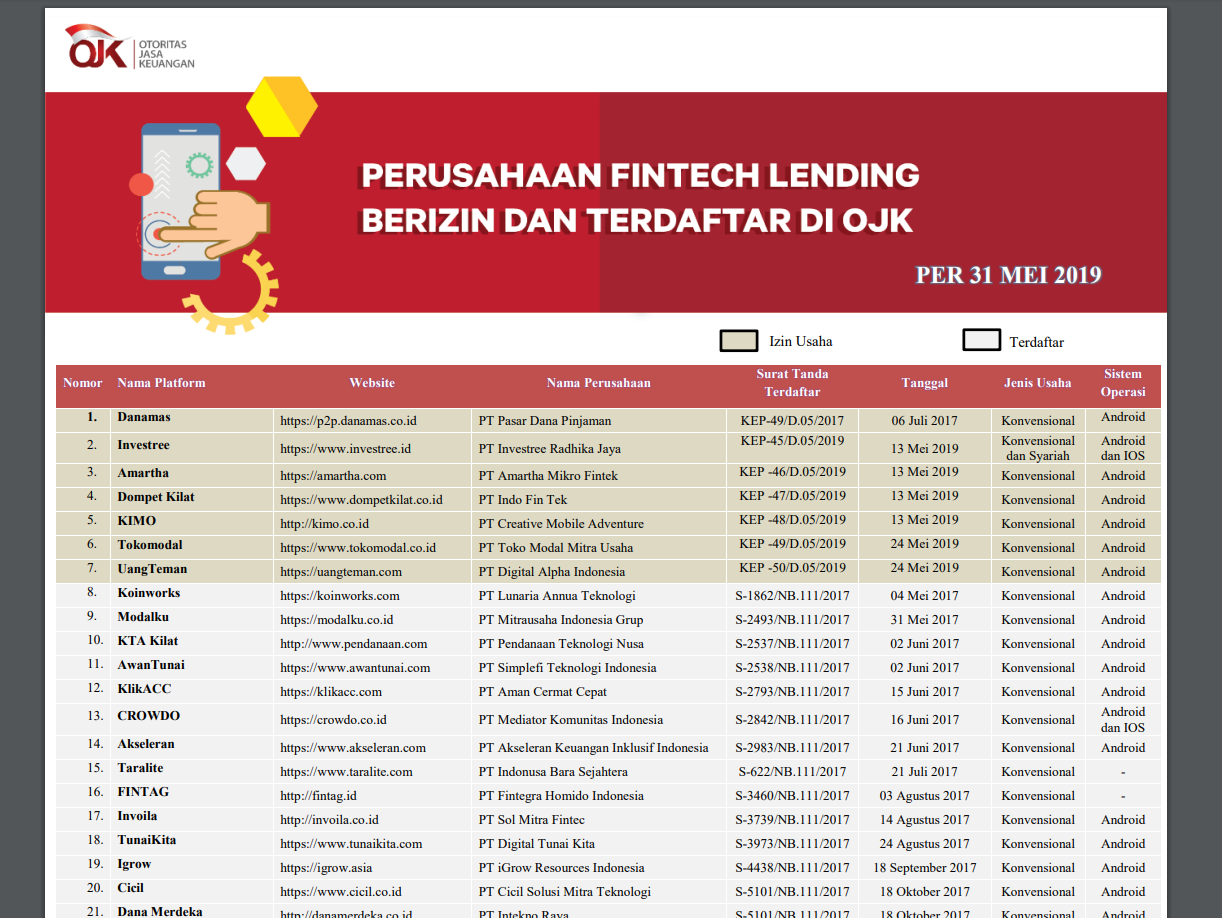
All of this inconsistency leads to a big void in the Pinjollist database, where a lot of companies share the same blank address.
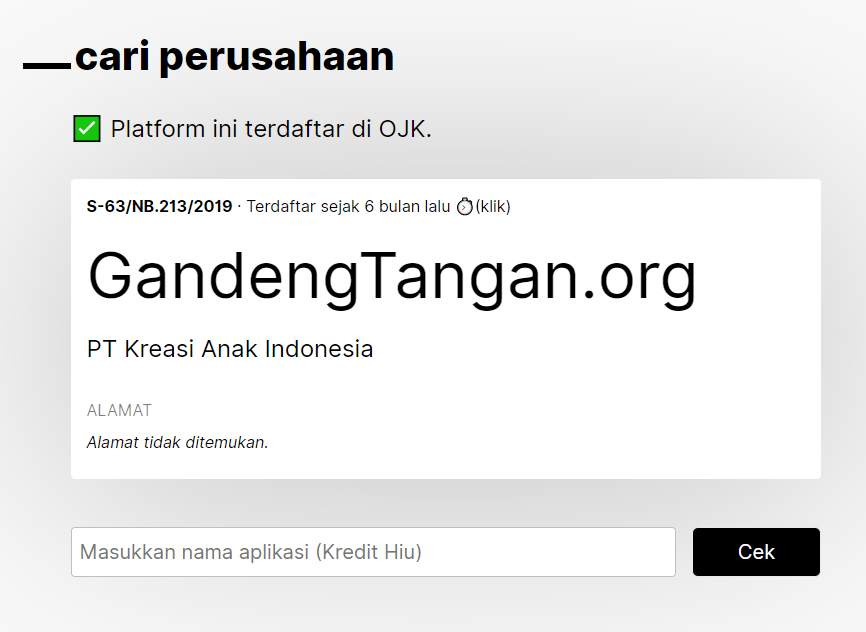
Wait, you published it where?
The OJK website does have a "fintech directory" section where - in a perfect world - all the data on registered lending companies and all its subsequent updates were published.
As expected, we found an Excel sheel complete with a list of all registered and approved companies as of June 2018. But that's it. Where did the others go? We did a deep dive into their website and found that all subsequent updates were published in the news section of their website.

We ended up having to do some digging through a mountain of press releases and all other nonsense in order to obtain these data. And not only that, all of the updates that were published on the news section were the ones published in PDF format. Meaning there's no easy way to add the contents of this file automatically into our database.
Note that after we download the 15 May 2019 data above, we later found out that a new data was published again in the same section for 31 May 2019, fixing some mistakes in the sharia/non-sharia labelling of some companies.
So, what's the point?
What gives? They provided the data, and I can read the data, so nothing's wrong on OJK's side right? However, I'd argue that your government agency doesn't embrace "open data" at all if the accessibility of your data is inadequate, both to humans and computers alike.
Let's say that I'm developing an app that helps measure someone's credit score by looking through a track record of all the lending companies they took loans from. The more they take out loans from trusted lending companies, the better their chances are of getting a higher credit limit. But in order to do that, I will have to lookup a list of these registered and approved lending companies. And manually inputting all those data from a PDF file will surely be a tedious process, a process which will take up a lot of your development time. So it would make everyone's lives easier by providing a public, searchable database of these companies.
In OJK's case, the data was provided inconsistently in every level. They were published in different places of the website, often making you dig through a mountain of non-relevant information before finding one. They have inconsistent file formats (Excel on one circular, PDF on the other). And more importantly, essential data (like the company's address and sharia status) are often missing and reappearing in these subsequent updates.
Have a centralised repository where you provide your data, and make it available in raw, machine-consumable format by default, like CSV (viewable in Excel). When able, also provide additional data formats like JSON (consumable by web APIs) and/or PDF (consumable by humans). The Jakarta Government does this well with their data.jakarta.go.id portal. They provide a single repository for all the public data they have, available in CSV and JSON format.
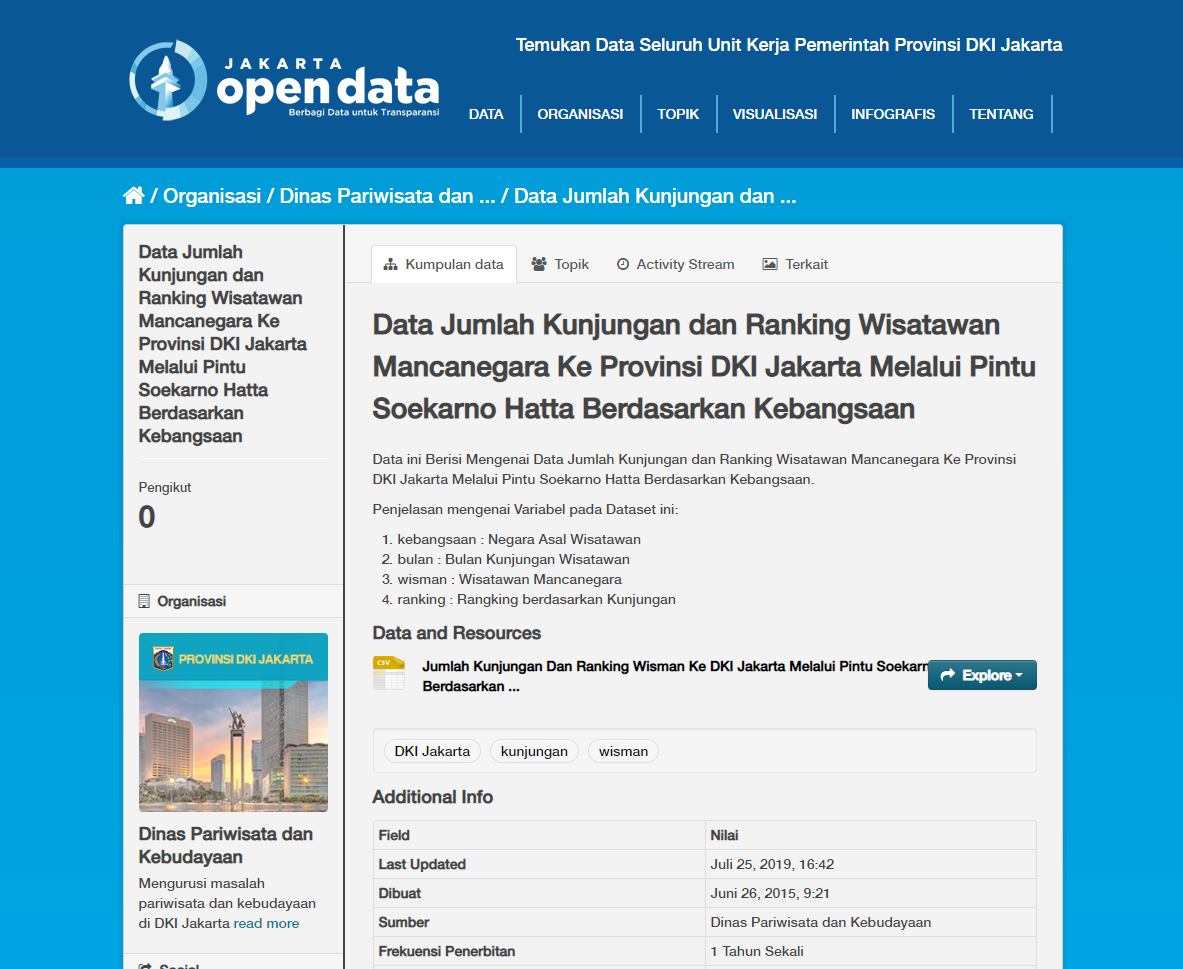
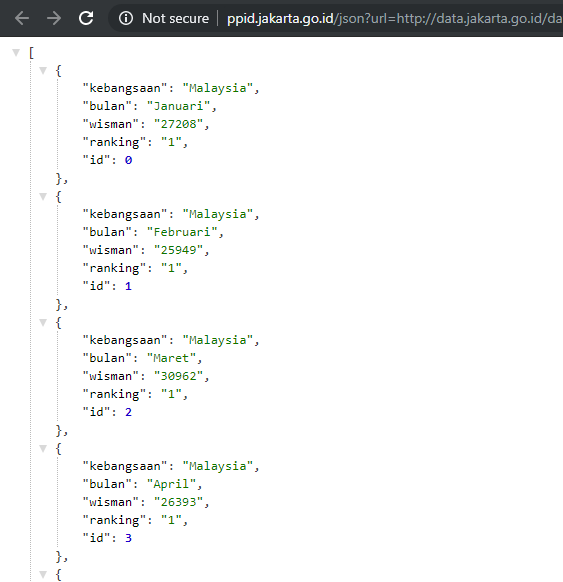
I don't know whether the OJK has a centralised database that keeps track. Maybe the data was kept in a single Excel sheet within the agency. Maybe each person within the division that oversees this has different ways of storing this data. But at least we can help them provide a clean, searchable public database of registered and approved P2P lending companies. Because we believe that financial literacy is important, with the first step being to educate people about which companies you should trust with your loans.
That's why @mathdroid and I built Pinjollist. To serve as an open data repository for everyone, including computers. All of our data are consumable through a public API, and for non-techies, we provide a Google spreadsheet of all the data we obtained from the OJK. All of our platform's source code, including the tools we make to process our data, are available on GitHub. If you have the time, do check it out!
Web developer based in Jakarta, Indonesia.